
The Private Capture of Public Genius
Essay I of Upstream of Everything
On January 24, 1956, the American Telephone and Telegraph Company was the largest private company in the world.
Its revenues amounted to almost 2% of the U.S. gross domestic product. It employed 746,000 people. It owned Bell Labs, the fabled research division that had already produced the transistor, the solar cell, information theory, and radio astronomy, while also actively laying the first transatlantic telephone cable. In the following decades, it would add UNIX, modern cellular telephony, the CCD image sensor, the first active communications satellite, and a long list of other scientific milestones. This singular stretch of intellectual output paved the way for Bell scientists to eventually collect five Turing Awards and ten Nobel Prizes.
By many metrics, life as a regulated monopoly was very good for AT&T.
Yet by the end of the day AT&T had signed away exclusive rights to every single one of its 7,820 unexpired patents, royalty-free, to any American firm that asked. AT&T would also license any future patents it filed at “reasonable rates.” A bleeding-edge, intellectual property treasure hoard was suddenly and irrevocably opened to the free market.
Antitrust officials initially sold the settlement as a triumph. The Justice Department called it a major victory, with one DOJ lawyer hailing it as “miraculous.” Despite AT&T already existing for decades as a regulated monopoly, with its returns constrained to a relatively conservative (by today’s standards) ~7% per annum, government regulators had pursued and established a landmark set of additional restrictions to curtail AT&T’s monopoly power.
Soon, however, public sentiment started to shift. Business Week called the decree “hardly more than a slap on the wrist.” A House congressional subcommittee would later deem it “a blot on the enforcement history of antitrust laws” for its perceived lenience on AT&T’s exclusive supply chains and vertical integration. Both the ratepayers, who subsidized AT&T’s vast research budget through its rate contracts, and many in the federal government believed this unprecedented economic concentration to still be far too dangerous for the Republic to continue unabated.
The now-infamous 1956 patent decree was just one half of a settlement negotiated over seven years between AT&T and the federal government. AT&T wanted to continue manufacturing telephone equipment through its subsidiary Western Electric, but regulators believed the vertical integration was foreclosing competition within the industry. The federal government itself was so conflicted about this issue that Secretary of Defense under President Eisenhower, Charles Wilson, pleaded with litigators that severing AT&T from Western Electric was “contrary to the vital interests of our nation.”
The second half of the settlement barred Bell from pursuing any business other than telecommunications.
A later analysis of the historical record revealed that 69% of Bell’s patents had little to do with telecom. Rather, they ranged from chemistry to semiconductors to metalworking, lighting, optics, and more.
The two halves of the settlement combined to ensure that this rich intellectual corpus, roughly 1.3% of all unexpired American patents at the time, became freely available essentially overnight and had a guarantee from Uncle Sam that the big, bad Bell Labs legal wolf would not come knocking.
Within just a few years, these released patents would generate almost $6B in follow-on patent value outside of the telecom industry. About $3.5B of that value came from patents filed by young, startup companies. One famous branch of that startup explosion ran through Shockley Semiconductor, then Fairchild Semiconductor, and eventually into the storied company known as Intel.
Intel’s co-founder, Gordon Moore (of Moore’s Law fame), would later describe this consent-decree-driven innovation cascade as:
“One of the most important developments for the commercial semiconductor industry. [It] allowed the merchant semiconductor industry to really get started in the United States. There is a direct connection between the liberal licensing policies of Bell Labs and people such as Gordon Teal leaving Bell Labs to start Texas Instruments and William Shockley doing the same thing to start Shockley Semiconductor in Palo Alto. This started the growth of Silicon Valley.”
Sediment
A generation of brilliant, publicly subsidized scientists built one of the most impactful clusters of technical genius the world has ever seen. Bell generated patents, invented products, and became the undisputed epicenter of American frontier science for decades. But how?
Imagine a carefully crafted rice paddy, terraced by exacting farmers who spent years precisely engineering a fertile environment. It looks like just a flooded field, but it turns out that rice is one of the few major crops that tolerates submerged roots. Since most weeds can’t tolerate submersion either, the water does the weeding. The deliberate flooding also cuts off the oxygen required for organic decomposition, so the soil retains more of its nutrients rather than burning them off like a dry, aerated field does. And the warm, waterlogged mud triples as an excellent habitat for nitrogen-fixing microbes. A well-tended paddy largely fertilizes itself, season after season, sometimes for centuries. This humble mud pond is actually one of the most productive growing systems humans ever designed.
AT&T’s unique economic position as a monopoly set the conditions for Bell Labs’ culture of deliberate experimentation, patient exploration, and delayed harvesting. Bell drew from an enormous and stable nationwide revenue base that didn’t have to be re-justified every budget cycle. American regulators set this revenue base through AT&T’s prices by using a fixed percentage return calculation on the capital it invested in the network. Here invested capital means switches, cables, buildings, and the like.
At a normal firm, research is a cost you minimize, but not at AT&T.
Every dollar spent on research at Bell Labs did two things at once. First and foremost, it was a no-risk, recoverable cost subsidized by U.S. telephone ratepayers under contract. Second, it was a wellspring of new, capital-intensive technology for AT&T to build and deploy. This capital expenditure expanded the very rate base on which its guaranteed return was calculated. The more money spent on these new technologies, the larger the absolute profit gained by the same regulated ~7% return.
This arrangement worked out very well for all parties for decades, but is not necessarily replicable. Nor is it obvious we should even try to recreate it because it came with real costs too. Inefficient over-investment, lack of price discipline, and most importantly an incentive to hoard inventions behind a monopoly wall all hurt ratepayers. But for much of the 20th century, these guaranteed profits did objectively create an expansive paddy field in which one technological innovation after another could flourish.
Frontier science looks different today. It's rooted in model weights and GPUs. It is flooded with token spend and agentic loops. It blooms in data centers.
While AI-assisted research is still young as a field, usage statistics show something big is happening in and around the major AI labs. Serious people are using this new technology to solve real problems, sometimes entire classes of problems, that were previously unsolvable. Protein structures, research mathematics, material design, drug discovery, and complex systems analysis are just a few of the fields where AI models are tangibly improving researchers’ abilities to clear humanity’s scientific roadblocks. But from where does this rich soil come?
It’s not really a secret.
OpenAI says it “primarily rel[ies] on publicly available information to teach [its] models how to be helpful.” Anthropic attempted to build a “central library of ‘all the books in the world’” to train its models. Sam Altman himself elaborates that their frontier models are trained on “the collective experience, knowledge [and] learnings of humanity.”
Strip the euphemisms and you’re left with the stark reality that these unprecedented capabilities were assembled out of the self-expression of every person across the globe who ever wrote anything down.
And the product built from this reality is, by the frontier labs’ own revenue, projections, and usage numbers, the most valuable thing built in a generation.
Anthropic’s annualized revenue run-rate rocketed from $87M in January 2024 to $1B by year-end, roughly 10x’d through 2025, and just hit $47B in May 2026. This makes it the fastest-compounding enterprise software company in history. OpenAI isn’t that far behind. An estimated 80% of the American workforce now holds a job where some portion of the work is exposed to these models. All of this impact was made possible by multi-week training runs over a data corpus measured in the lifetimes of billions.
This is the private capture of public genius.
A frontier model is the compression of a massive amount of training data into numerical weights. The combined collection of books, forums, code repositories, manuals, papers, chat logs, transcripts, court cases, essays, comment sections, articles, tutorials, and every errant thought scrapeable by the frontier labs’ army of spiders crawling across the internet and beyond is staggering.
In a way, its incomprehensibility is almost like psychic armor. It’s too big to understand directly.
Consider a wild river delta. As water runs from highlands to the sea, it erodes the land it travels through and carries the debris downstream as sediment. Silt, sand, clay, and all manner of organic material, scoured from every inch of tributary and riverbank, from plowed fields to rugged hillsides, end up aggregated in the delta. So does the richness of every life the river supports along the way. A continental watershed, swirling, accumulating, and ultimately settling at its terminus. The vast volume of disparate material combines in the delta to form something lush, strange, and alive.
And what is the sum of all human knowledge if not this?
Every cluster of letters scraped from the pages of history (the literal tokens an AI model ingests) is a single grain of silt deposited by the ever-flowing river of man’s exploration. Pile enough grains and you understand the movement of the stars. Stare long enough at the mud and you see the structures of logic itself. The large language model’s transubstantiation of alluvial soil into answers is the grand harvest of the society that grew it.
But subtract the dirt and there is no delta.
Subtract the corpus and there is no harvest.
There is nothing.
The model did not learn to reason in a vacuum. It absorbed rationality by observing rationality over and over and over again. Its powers of generalization are downstream of every example, correction, and argument it subsumed. A human decision somewhere in the echoes of history, culture, and science set the stage for today’s chatbot response. This cultivated intelligence grows from the sediment of human sensemaking, but there is no sediment here that was not deposited by someone.
Many of those someones are dead. They wrote the ancient texts, tested the baseline science, and recorded the history of the world from antiquity for the benefit of all of us still here. But too, many of those someones are alive. They are writing the working code that the model spits out. They’re pushing that baseline science past its frontier. They’re organizing and investigating and acting upon and reacting to the infinite feed of current events. Any response germane to today is borrowed from somebody.
In fact, you’re one of those somebodies. Literally.
Your 2am shitpost. That eloquent reply to a stranger’s essay. The scathing restaurant review you left. Your captions, comments, inside jokes, and all of your public conversations. Every contribution you ever made to the infinitely branching stream of digital communication, big and small, has settled somewhere in the delta.
Everybody Owns the Internet
The Nile River delta fed Egypt for five thousand years. The Mekong and the Ganges regions still feed hundreds of millions today. It’s no coincidence that every cradle of civilization owes its formation in whole or part to the floodplains and deltas of great rivers. These areas supported humanity through our most primitive eras with little more than the inherent richness of their raw materials. This dirt is begging to burst forth with life, yet somehow the richest farmland on earth is, almost without exception, accidental.
So too goes the internet.
We myriad digital denizens of the information superhighway did not set out to create a training corpus. We wrote for ourselves and for each other. We joked, argued, taught, complained, flirted, and debugged our way into this aggregated mass of interrelational raw material now harvested by private capital. The field of economics (which is also in the corpus) has vocabulary for this.
To categorize any resource, economists ask two questions. Is it excludable, and is it rivalrous?
More plainly, can you stop people from using it, and does one person using it diminish what’s left for everyone else?
There are caveats and sub-categories, but this simple test gives us a map.
If a good is excludable and rivalrous, it is a private good. Think about a sandwich. If I eat it, it is gone, and the law protects me from sandwich thieves.
If a good is excludable but mostly non-rivalrous, it is a club good. A Netflix subscription is a club good. If I watch a movie, you can still watch it too, but only if we both pay to have access.
If a good is hard to exclude people from using and rivalrous, it is a common-pool good. A pasture is the classic example. Many farmers can access the pasture, and while one cow grazing does not destroy the field, add enough cows and they’ll eventually gnaw the grass down to dirt. This is the infamous “Tragedy of the Commons” problem.
Finally, if a good is hard to exclude people from using and non-rivalrous, it is a public good. Streetlights are public goods. Once the street is lit, all of us can walk beneath the light, and my doing so does not darken the road for you.
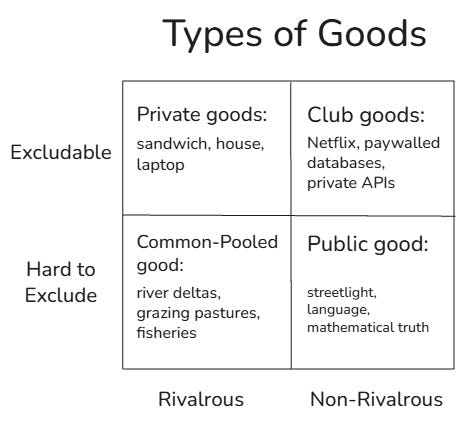
Private and club goods are typically governed by profit-seeking actors and the legal system in which they operate. Public goods are primarily governed by governments or nobody, and common-pool goods tend to exist in a liminal space where everybody seeks the benefit and nobody wants to own the costs of upkeep.
The frontier labs generally argue that data on the internet is open for training under fair use copyright regimes. In economic terms, this argument implies the internet is a public good. The mass scraping, ingestion, and use of internet data for training does not destroy that original data. Every blog post, tweet, and flame war is indeed still there and for the most part accessible. Nobody clearly owns it.
Does the platform you post on own your posts? Do you share ownership with the platform? Can this relationship change over time?
You did post it online for free after all.
Except granting access is not the same thing as giving license. A library card gets you access to read a book, not to photocopy the entire library. Buying a national park pass does not confer logging rights. Visiting an open store does not entitle you to steal its inventory. Public access to work on the internet does not automatically confer usage rights.
And there is a second, deeper problem with “you posted it, you accepted this.” Until very recently, the LLM training data use case did not exist and could not have been reasonably foreseen by a party posting online. A blogger from 2008 could not have consented to their work being used to train a language model today, because that wasn’t conceivable back then. Consent can’t be assigned backwards in time, least of all for a sci-fi subplot turned real.
The current legal battleground for LLMs is a story of non-resolution.
Notably, despite our moral intuition, access and consent are irrelevant to the frontier labs’ primary legal defense claims of “fair use.” Instead, courts evaluate four criteria as they rule on a fair use defense. They look at the purpose of the use of copyrighted material, the nature of the work, the amount used, and the effect on the market for the original. In practice, these four items generally collapse to two important questions.
Is the new work transformative, and does it harm the market for the original?
In June of 2025, Judge Alsup ruled in Bartz v. Anthropic that training on legally acquired books was “quintessentially transformative,” but building its library from pirated books was “inherently, irredeemably infringing.” With this mixed victory, Anthropic faced a theoretical exposure of up to $70B in copyright damages and quickly settled the case for $1.5B a few months later. This is the largest copyright settlement in U.S. history (so far) and granted no future licenses to Anthropic, nor did it clarify any law going forward.
In a related ruling, Kadrey v. Meta, Judge Chhabria found LLM training similarly transformative and grudgingly ruled the evidence of market harm insufficient. In his ruling he criticized the plaintiffs for putting forth almost no evidence of market dilution and suggested that LLMs’ ability to flood a market with AI work similar to the training data "will often cause plaintiffs to decisively win the fourth factor—and thus win the fair use question overall—in cases like this."
Complicating the discussion further, the U.S. Copyright Office issued a non-binding report in 2025 concluding that public availability does not inherently allow fair use model training. As of this writing there is no settled legal standard for measuring LLM-driven market dilution, but this is primed to be a major confrontation in future legal decisions. Already, dozens of lawsuits and policy fights are testing the frontier labs’ evolving training-data defenses.
The labs’ most seductive defense is also the simplest.
“It’s just reading” is a common refrain among technologists defending AI model training, and it is a compelling argument. Every writer alive is built from the books they consumed. Nobody sends Hemingway’s estate a check for being inspired by The Old Man and the Sea. If the model is just another reader, it owes what every reader owes: nothing.
A person who reads ten thousand books in their lifetime becomes one more writer, working at human speed, publishing at human volume, and returns their sediment to the delta one grain at a time. A model that reads everything instead becomes a printing press that prints more printing presses. It spits out work at industrial volume, trains its successors, and competes with the very writers it consumed, at the push of a button. Inspiration never diluted a market, but printing does.
The invention of the Gutenberg press around the year 1440 ultimately led to the passage of the Statute of Anne in 1710. A cartel of powerful book publishers lobbied British Parliament to restore their monopoly rights over the book trade, and Parliament instead vested the right in authors as legal owners. The incumbents asked for protection and the public’s representatives handed ownership to the creators.
This statute established the basis of modern copyright law. Before the printing press, this wasn’t really necessary because mass piracy was practically impossible. The new technological landscape triggered a reproduction cascade that overwhelmed legal systems designed for a previous era's problems, but that reckoning took over two and a half centuries to play out.
The printing press that prints more printing presses will not let us wait that long.
Spoiling the Delta
On its face, the rich river delta that holds the deposits of humanity’s collective knowledge does appear to be a public good. Frontier labs scraping and ingesting the massive sedimental body of the internet does not destroy the original materials in a literal sense. The courts have already started ruling in that direction, but, like many legal rulings, this is narrowly correct, and completely misses the point.
A flat understanding of the training corpus question misunderstands how the internet’s functional layers and its participants actually interact. So far we’ve analyzed just the text layer. The webpages, articles, posts, comments, and everything else that the frontier labs scraped into a training corpus are one obvious piece, but there are many other layers of the internet, and they set the conditions for the text layer to exist at all.
Besides the obvious technical layers like the protocol or access layer, we must also consider the discovery layer, the attention layer, the contribution layer, and the integrity layer of the internet along with the flow of behavior between them. The continued utility of the internet depends on people finding, engaging with, contributing to, and ultimately believing in the value of the things they access online.
When framed as a static corpus, it is not obvious that the internet is damaged by AI training runs. Certainly it’s not damaged in the same way too many cows can damage the grass in a pasture.
Instead, what’s actually damaged is the complex system that evolved to enrich that corpus in the first place. The internet is a stack of interconnected public, club, and common-pool goods. Different layers react to and reinforce each other to make the whole valuable yet also vulnerable to the specific harms introduced by LLMs.
No human maker can compete with the raw volume of generative output working to overwhelm our algorithms and attention spans. The layers of the internet behave less like a pasture here and more like a road or an email inbox. They’re non-rivalrous up to a threshold, then catastrophically rival.
Consequently, the incentive to earnestly participate in the web diminishes with every AI variation of a derivative of a tweet of a derivative. Why make and share things online if you won’t get seen, can’t compete with the 10,000 variations of AI dogs dancing to upbeat electronica, and when you finally make something genuinely impressive the top comments just accuse you of being AI? The ability of generative AI tools to flood any corner of the web with media, slop or no, at effectively zero marginal cost might just be the final pedal stuck to the floor of the Spam-Everyone-Forever-Bus that left the station way back in the 90s.
This is an important moment. The naïve harvesting of the fertile corpus layer is a broadside against the very people who made it possible. Some parts of the web have likely already broken. If we play this wrong, the entire internet may irreparably break. Yet we’re not without tools to help us here.
We already know how to protect a commons. Elinor Ostrom won a Nobel Prize in 2009 for documenting how Swiss alpine pastures, Japanese forests, and Spanish irrigation networks sustainably shared their commons for centuries. She identified eight conditions for enduring commons: clear boundaries on who may draw from it, rules matched to local conditions, the people affected having a say in those rules, monitoring by parties accountable to users, graduated penalties for overuse, accessible ways to resolve disputes, recognition of the community’s right to organize, and governance nested across scales.
Run the internet through this checklist and almost none of the eight conditions hold. Its boundaries are hazy, fueled by everyone and fenced by no one. The people who fill it have no say in how it is governed. Its rules are unclear and only sporadically litigated, and then only by a handful of well-capitalized parties. Oversight is thin where it exists at all, always retroactive and never proactive. There is no monitoring, no graduated penalty, no shared venue to resolve disputes. It is, in Ostrom's precise sense, not a governed commons at all. It is a common-pool good with the plug pulled.
That’s why we’re in this mess. Much like in the era of the oozing Cuyahoga and the slurry-drowned Buffalo Creek, we’re staring down a cyberindustrial runoff disaster poised to spoil the entire delta.
Attribution Collapse
The river still flows for now. Fresh sediment continues to settle in the delta, the corpus layer continues to grow, and the labs continue to scrape.
And as they scrape, they continue to compress the colossal delta of the internet into fixed sets of weights, but this ongoing ritual manifests another problem. This time a problem of value, not quality.
Specifically, the problem of who gets paid for what value.
According to the frontier labs, all of these billions of scraped data points are somehow individually worthless, yet collectively worth trillions.
By worthless, they mean that no individually scraped work is needed in the training set. Remove any one piece and the model barely notices. Therefore no single work really matters. Therefore no single work is owed payment.
But if we can unslack our hanging jaw long enough to chew what they’re feeding us, we can see the individual data points are clearly not worthless.
This is a rhetorical trick. It’s doublespeak from a self-appointed detective declaring “since we can’t figure out exactly how much jewelry was stolen, no charges can be filed.” Except they’re also the thief. And just opened up a jewelry store.
This “aw shucks” is, of course, preposterous. Poor accounting practices do not erase the clear transfer of value, especially when the accounting is impossible.
In principle, the accounting is impossible from a legal standpoint because copyright law was built to police discrete copying. Court precedents assume infringers copying enumerable works from legible parties. Large language model training is the statistical absorption of billions of works at once. It’s a different shape with the same moral essence, but since the extracting act is a new mechanism, the legal instrument cannot quite grip it (yet).
But even more concerning is that attempts at quantitative accounting may just be mathematically incoherent.
The leading formal method to value a training input is the Shapley value, which averages an input's marginal contribution across every ordering in which it could appear. But that number isn’t a property of the work itself. It’s a function of the work’s relationship with every other work in the training set. The same document in a different training set will have a different Shapley value. Train the same model twice and, because training is stochastic, the Shapley value might change from run to run. Researchers do not even agree that Shapley is the right contribution metric, and calculating true Shapley values for frontier-scale models is computationally infeasible. These models can take weeks to train once; exact Shapley accounting would require retraining across impossible combinations of inputs. So as of today, there is no objective valuation scheme for calculating any work's specific share that would not be litigated into oblivion the moment it was implemented.
Individual attribution for LLM training at frontier scale will not work for the foreseeable future. You cannot pay people in proportion to their contribution because no administrable, specific share exists. This is the root of the misdirect. The labs interpret this fact to mean “if we can’t attribute then we owe nothing.”
I argue that it means you can’t pay proportionally, but the payment is still owed.
Paying Public Genius
Here is the true shape of the problem. Individuals create singular work, but never in isolation. The internet is communal by nature. Both collaboration and conflict feed the whole.
Branches grow stronger when pruned. The richest soil is built from rot. Vines climb by contact. Friendly minds cross-pollinate ideas while predators and prey run each other faster. This teeming mass of garbage and brilliance is valuable precisely because of the varied relationships each piece has with the others. In the living distance between them, human cognition buds, blooms, and bears fruit. Despite the romance of solitary genius, the internet is a team effort.
And if you cannot identify the most valuable player, you pay the team.
That payment is a royalty. It is a dollars-and-cents accounting of the public genius LLMs extract from the best and worst of us.
Call it the Corpus Royalty.
The frontier labs pay a fixed share of gross revenue into a public fund. The fund pays every eligible American the same amount each year. Any mechanism cleverer than this reimports the measurement problem, and it dies ten thousand quibbling deaths in the courtroom.
As LLMs fuse themselves into the internet and reshape the incentives for human expression, a royalty becomes the only coherent answer to the question of compensating collective, unattributable contribution. Frontier labs cannot continue their harvest of the internet unfettered. They must replenish the upstream sources that feed the fertile delta their models depend on, or the internet will become unrecognizable within the decade.
We’ve built smaller versions of this machinery before.
When private entities profit from shared resources, we recognize the public is owed a claim on the proceeds. The Alaska Permanent Fund follows this intuition. Every eligible resident receives a share of resource wealth no one resident can individually claim. Since we cannot reliably measure what any single person’s words are worth to a model, the distribution should reflect the failure of attribution rather than pretend to solve it.
When individual claims are too numerous to price one by one, we do not pretend they have no value, and when private entities damage public spaces, we declare they are culpable for that destruction. After a century of burning rivers, Congress built Superfund in 1980 and handed the cleanup bill to the polluters, for dumping that was legal when it happened. Nobody had to trace which barrel poisoned which well. The industries that profited from the toxic waste paid to restore the ground.
Some will say the Bell precedent argues for opening the weights, not cutting checks, but remedies follow wounds. In Bell’s case, competitors were wounded by intellectual lockout, so the remedy was access. Today, contributors are wounded by the extraction of intellectual value. It follows that payment is the remedy that makes the wounded whole.
The Corpus Royalty may be small at first. Perhaps just enough for an extra case of beer per year, but the amount matters less than the standing it confers. It shows the public they are more than just raw material exploited to train increasingly large language models. If the labs are right about what they are building, beer money becomes grocery money becomes rent money that grows with the labs and their revenues. If the labs are wrong, it won’t be because a royalty killed the business model. Normal people’s lives, arguments, questions, jokes, corrections, and creations help sustain the corpus those models consume, and this brings them along proactively instead of parasitically. The corpus is either essential or it isn’t. If it is, it has a price, and industries pay for essential inputs every day. The labs have already conceded as much in their licensing deals with Reddit, News Corp, and the Associated Press.
This is not welfare, because welfare assumes the companies are subsidizing the public, when the subsidy runs the other way. This is not charity, because charity implies nothing was received in return. This is not a tax, because a tax treats the surplus as company property subject to public claim.
This is restitution.
The legal word for this shape of problem is unjust enrichment, but the common law version is too small for the thing now in front of us. In ordinary law, unjust enrichment asks whether one party has benefited at another’s expense under circumstances that make keeping the whole benefit inequitable.
The frontier labs have received such a benefit by converting an uncompensated, massively aggregated, publicly generated corpus into private infrastructure-level value while threatening the conditions under which that corpus is renewed. They have done this at a scale and level of diffusion that individual litigation cannot sensibly price. The size of the problem tells us the remedy must be collective.
A royalty paid on value rooted in the public corpus is a return. What flows back to the internet is owed, not gifted. This is a royalty on public genius.
A royalty is only part of the solution. It’s one piece of a larger system of contribution and sustainment. It does not replace copyright claims or private licensing contracts. Those can and should still happen where ownership is legible. The royalty solves for the unattributable long tail of creativity that cannot organize, negotiate, or litigate its way into the licensing market.
What the labs are doing is not new in kind, only in scale. This is the private capture of public genius at civilizational scale. This should not surprise us. Corporate entities built atop public support often try to privatize the upside while socializing the conditions that made it possible. Special organizations have abused their special status this way before. The difference is that this time the affected class is everyone at once.
Perhaps we have been building toward this since we first scratched marks into clay more than 5,000 years ago. We’ve recorded, collected, and categorized our way into fragility. Once every externalized thought, every written word, every diagram, flourish, and turn of phrase can be rolled into a mechanical genie, who could resist the temptation to sell it back to the people who supplied it?
This is why the public needs a claim. The frontier labs increasingly seek the privilege and power of a utility without accepting the public obligations that come along with it. A Corpus Royalty restores some of the balance in that bargain by letting the public collect a share of the wealth it made possible. The public already bears the downside of the world these models are creating and deserves part of the upside.
The Corpus Royalty ensures humankind’s scattered sparks of brilliance have skin in the game they helped create.

This is excellent! Belongs in the LRB.
This slaps. Really glad I read it