
Communication and Entropy
“The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point.”

That’s how Claude Shannon opens his landmark paper “A Mathematical Theory of Communication” in 1949 when he published when he was (checks notes) 33 (oh thank god I still have time lol jk ahhhh).
What a doozy of a title. I mean.
Can you imagine naming your paper something like that? In a technical journal??
Read by Electrical Engineers???
The audacity is staggering.
and yet, he delivers, man. It’s a wild read. Lots of math, but don’t be scared.
The math is cool. Look at it for sure. but we're here for the ideas so we can set sail on the S.S. Imagination
You see, many people view Claude as the inventor of the Information Age. Sure there were others that made real contributions to the field (like Nyquist and Hartley), but this paper really kicked it off with two big ideas: Channel Capacity and Entropy.
Personally, I think of Claude as having the best Blue Steel in the science biz (don’t believe me?), but that’s neither here nor there.
{kind=link}
Anyway, on to the ideas!
Information Theory underpins pretty much everything technological we use today. Check out this block of stuff that uncle Wikipedia says are applications of these ideas
Applications of fundamental topics of information theory include source coding/data compression (e.g. for ZIP files), and channel coding/error detection and correction (e.g. for DSL). Its impact has been crucial to the success of the Voyager missions to deep space, the invention of the compact disc, the feasibility of mobile phones and the development of the Internet. The theory has also found applications in other areas, including statistical inference, cryptography, neurobiology, perception, linguistics, the evolution and function of molecular codes (bioinformatics), thermal physics, molecular dynamics, quantum computing, black holes, information retrieval, intelligence gathering, plagiarism detection, pattern recognition, anomaly detection and even art creation.Not too shabby.
So ol’ Claude defines general communication with the following nifty visual

Sleek and simple. And powerful.
Every message in a communication system is conveyed via a signal that has a source, a mechanism to encode and communicate that message (transmitter), the message (signal) itself, an external force that can disrupt and modify the signal in some, typically undesirable way (noise), a mechanism to receive and decode that signal (receiver), and the destination which interprets the decoded signal.
Think of you sending an email. Most times you hit send and it goes fine, but every once in a while, the email recipient might spill coffee on her lap while reading and skip a line in the email you just sent. This could cause her to miss a key piece of information (like a meeting date and time). That’s noise.
So. Who cares?
Let’s look at the problem more closely (here it is again for both of us):
“The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point.” hmmm.
He goes on to say the “messages have meaning; that is they refer to or are correlated according to some system with certain physical or conceptual entities.”
This basically means that a message (for example an email again) has data (the letters that make words in the email “Hi Bob - this is Alice.”) and that data adheres to some system (the English Alphabet in this case) and that system has characteristics that convert those letters into meaning (things like grammar, syntax, punctuation, definitions, and the generally shared agreement of 1.5 Billion people of the basic rules therein).
Then like a true engineer he says this:
“These semantic aspects of communication are irrelevant to the engineering problem.”
What a savage.
But his point is beautiful and well taken. He describes next that the most “significant aspect” is how each message is just one selected from a larger set of possible messages.
In this case we can think of the message “Hi Bob - this is Alice.” as just one specific message (an ordered combination of numbers and letters and symbols) from the complete set of all 23 character messages that could be sent using the first 128 ASCII codes.
More precisely, “Hi Bob - this is Alice.” is just one out of the 128^23 total messages we could send with a 23 character message.
This is a total set of 2923003274661805836407369665432566039311865085952 distinct messages that can be sent or more succinctly said as 2 quindecillion 923 quattuordecillion 3 tredecillion 274 duodecillion 661 undecillion 805 decillion 836 nonillion 407 octillion 369 septillion 665 sextillion 432 quintillion 566 quadrillion 39 trillion 311 billion 865 million 85 thousand 952 possible messages in the set. lol.
There’s only one “Hi Bob - this is Alice.” in all of that possibility.
Crazy.
Also, don’t “um actually” me on Twitter, nerds. I know a bunch of those ASCII characters are control codes for non-printing purposes. Just bear with me.
ImAgInAtIoN, remember?
{kind=link}
But the key takeaway here is there are a LOT of possible messages, but with some basic logic we realize that the vast majority of those message are completely useless, unintelligible garbage (like literally “HASJFAKJFAKJFHASHFTTTAT”).
unhelpful.
BUT with some work, we can discern probability distributions of the frequency of characters or words based on datasets of actual, useful communication in the target language and then apply those distributions to our character set to potentially approximate actual meaning!! I’m gonna let Shannon do the work.
See how Shannon demonstrates this by applying more and more useful probability distributions at each layer:

In a way, this is kind of what babies do to figure out how to communicate.
Isn’t it insane to see meaning (or what feels tantalizingly close to meaning) materialize from math? What’s even more insane is that none of this matters for communication (or at least the math behind how the abstraction of communication works). So even though it’s fun, let’s put this “letters are meaning that is mapped to the arbitrary English Alphabet set of rules” thing somewhere else your mind because it’s not why we’re here.
Let’s talk about flashlights.
Think about if we had a flashlight and a friend (if only…) and we want to talk to each other by turning the flashlight on and off rather than talking (Note: this scenario is sort of stolen from CODE ← definitely read if you like computers and logic gates, but especially read it if you don’t know what that sentence means).
If you’ve ever done anything computer science-y you already know where this is going - Morse Code. You don’t need to learn Morse Code for this, but you do need to understand that there exists a way to communicate using dits and dahs (dots and dashes) that are conveyed (transmitted anyone?) by the flashlight through a medium (air in this case) that is received by our friend’s eyeballs (receiver) and then they decode our message with their brain. Communication!
And the medium (the channel for those keeping score at home) we choose to communicate in has an inherent upper limit on the capacity of information we can send across it for any given moment. Compare the channel capacity of these flashlights against our voices (which we’re still not using). You can send more information per unit of communication through your voice because of course you’re better at talking than flashlight morse coding so the channel capacity for your voice is essentially higher than the flashlight channel. You can do a lot of things to increase channel capacity and there’s whole a lot more to this, but that’s the gist of what you need to know. Also, here’s a formal chart of the channel constraints in telegraph communication because it’s cool.
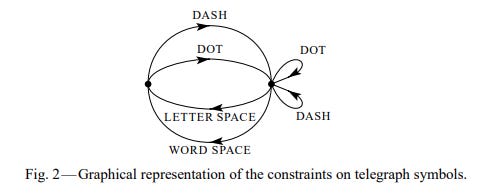
We’d love to communicate at maximum channel capacity all the time, but the real world is messier than we’d like.
The further away we get from each other, the dimmer the lights get because the flashlight maybe can’t shine bright enough because of it’s Lumens/Wattage ratio isn’t high enough for our environment or maybe it gets foggy as we’re walking away from each other or maybe there are cars passing in front of us as we try to flash messages at each other.
All of these things are noise that interfere with our communication signals.
All of these noisy factors reduce the information content (and subsequently the value) of the signal we get across to each other.
Losing those bits (literal bits in this case) erodes the meaning we’re trying to convey with each message (and makes us communicate below channel capacity) and Shannon wanted to understand the mathemagics of all this.
So he defined Entropy. nbd.
Entropy represents an absolute mathematical limit on how well data from the source can be losslessly compressed onto a perfectly noiseless channel (aka a channel that transmits info at maximum capacity) and it can be understood as the uncertainty or surprise (i swear on my life) content of a random variable.
It’s weird I know. In times like these, I find it helpful to think of Alice’s email.
Getting the string “Hi Bob - this is Alice.” from a truly random sequence of 23 characters with 128 possible choices (without any probability functions derived from the rules of the English Alphabet applied to the characters) would be very surprising.
However, getting that sequence from the same 128 choices that had a probability function (derived from those rules) applied to each character means the coherent message is more likely to appear and makes it intuitively less surprising for it to show up than in the unweighted, previous case.
So the second scenario has a lower Entropy because we’re surprised less for the same length string message.
Intuition is hard.
Just internalize that less certainty (or inversely MORE uncertainty) means more Entropy means more surprise. Accordingly (for all you math lovers), a uniform distribution has maximal Entropy.
So more noise means more Entropy in your communication system means more surprise at the message in the outcome.
Which brings us to cables (and computers)!
Computers are real (unlike birds).
We’ve worked super hard to them work really consistently and made conditions good and increased reliability to super high levels, but the fact is that we live in a physical world and everything in the cloud also has a physical presence that is actually roomfuls of servers and CPUs and GPUs and CDNs and routers and edge components and all this super cool stuff but it’s all like…real. Like you can hold it (and it breaks sometimes). We forget that a lot of the time.
And this real stuff is constrained by real problems and is subject to noise just like everything we’ve been talking about.
I (co)wrote a thesis a while ago on a certain type of noise in a specific type of optical fiber that is caused by a particular source of randomness (stimulated Brillouin scattering, two-mode, electrostriction respectively).
Don’t worry, I don’t understand it all either - science is nuts tbh.
It was hard and complex project (really not sure how academics spend years studying one really, really specific thing) but also wow because I got to look super closely and explore the math behind why you can’t just lay a single fiber optic cable from here to Antarctica and give the penguins gigabit speeds. Unfortunately for penguins (and us), physics just doesn’t work like that. There are inherent properties in materials that limit our ability to do the things we want to do with the sand crystals and lightning the bring us our memes.
The point is that the physical infrastructure we use to communicate vast amounts of information across the planet every single second is subject to noise and entropy that is both external (magnetic storms) and internal (seriously electrostriction in a cables basically causes information degradation because we’re shoving pulses of electricity into it and the cable is screaming and writhing in agony from said pulses). If you’re into hearing more about this sort of thing, here’s a fascinating book about Lord Kelvin and his attempts to lay undersea transatlantic cables (which turned out to be pretty hard).
But it’s things like oceans that reduce our ability to send information at maximum channel capacity in technology and this is what it looks like IRL!

So we can send information in messages and we want to make sure that we get our messages across regardless of the medium, right? But how can we do this if noise/entropy is trying to ruin our lives? By making our communication systems redundant, specifically in this case with error detection and correction.
There’s a lot of ways to achieve that goal. We can send the same message a ton of times, we can write our messages in a way that when we figure out they’re wrong we can correct them during the sending, we can keep track of a mathematical mapping of our data and do some more math on it to make sure subsequent messages are built off the previous ones (that one sounds familiar…), or any number of cool tricks, yet they all stem from that first problem (of course) of recreating a message somewhere other than where it originated and we forget that sometimes. This feels oddly…universal.
ok what are we talking about again?
Communication.
Channel capacity.
Entropy.
Redundancy.
and now
People.
People
yea people.
Almost everything you’ll do today involves some sort of communication element with others or your future self. This essay is a one to many discrete message that I hope conveys enough information content through the v noisy channel that is the internet. I already know there’s going to be issues because substack is warning me that Google will truncate this email. Noise. whoops.
Your code commits (and comments) are quantized messages as well. That project you’re working on, that presentation you did, or that email are too.
All of these activities are bounded by the same set of constraints that were mathematically formalized by classy Claude 70 years ago.
There’s a finite amount of information content you’ll send with each keystroke limited by channel capacity of your intended medium.
There’s Entropy at every point between A (you) and B (everyone else).
Your explanations and over-explanations and reminders and check in meetings and circle backs and pings and one on ones are all attempts at building redundancy for your intended communication.
We’re all just trying to send a signal through the noise.
I hope this added value to your day.
Please share this with someone who might find this interesting!
If you have any thoughts or questions about this essay - Let’s Chat
To hear more from me, add me on Twitter or Farcaster,
and, of course, please subscribe to Wysr